Patlytics Expands Life Sciences Capabilities with Sequence Listing Management for Patent Drafting

Life sciences patent work presents challenges that are unique to this technical field. In pharma and biotech, the substance of an invention is often captured in biological sequences. A biology focused application can contain tens or hundreds of sequences, each running anywhere from a handful to thousands of amino acids or nucleic acids.
Life sciences practitioners have historically engaged in a tedious process: draft an application, include every sequence with proper support, and then painstakingly check each sequence again - a labor intensive process with a high risk of error.
While AI has improved patent-related workflows, LLMs don't handle biological notation well, and a single misread or dropped character can mean losing coverage over an expensive asset. Those consequences are unacceptable for pharma and biotech companies that spend millions on R&D to create billion-dollar products.
Patlytics is now introducing a purpose-built approach to biological sequence listing management, offering a more streamlined workflow that integrates seamlessly in our market-leading, end-to-end patent platform.
With flexibility across use cases and technologies being essential, this expansion offers transformative features for our life sciences prospects and customers, which include 40% of Am Law 100 firms and a comparable number of innovative pharma and biotech companies.
Sequence Listing Management
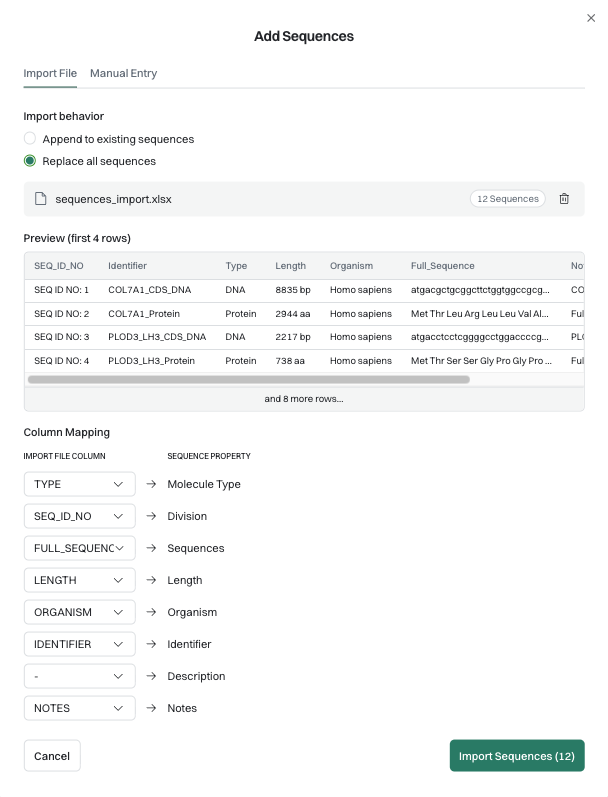
Amino acid and nucleic acid sequences are central to claim scope for most biotech inventions. Traditional drafting involves parsing the sequences. Software tools can improve this process over manual management, but either way, the workflow is labor intensive. LLMs have also been suggested as options for sequence management, but the nature of the sequences (seemingly semi-random sequences of text) and limits in context window size limit the usefulness of general LLMs in this area.
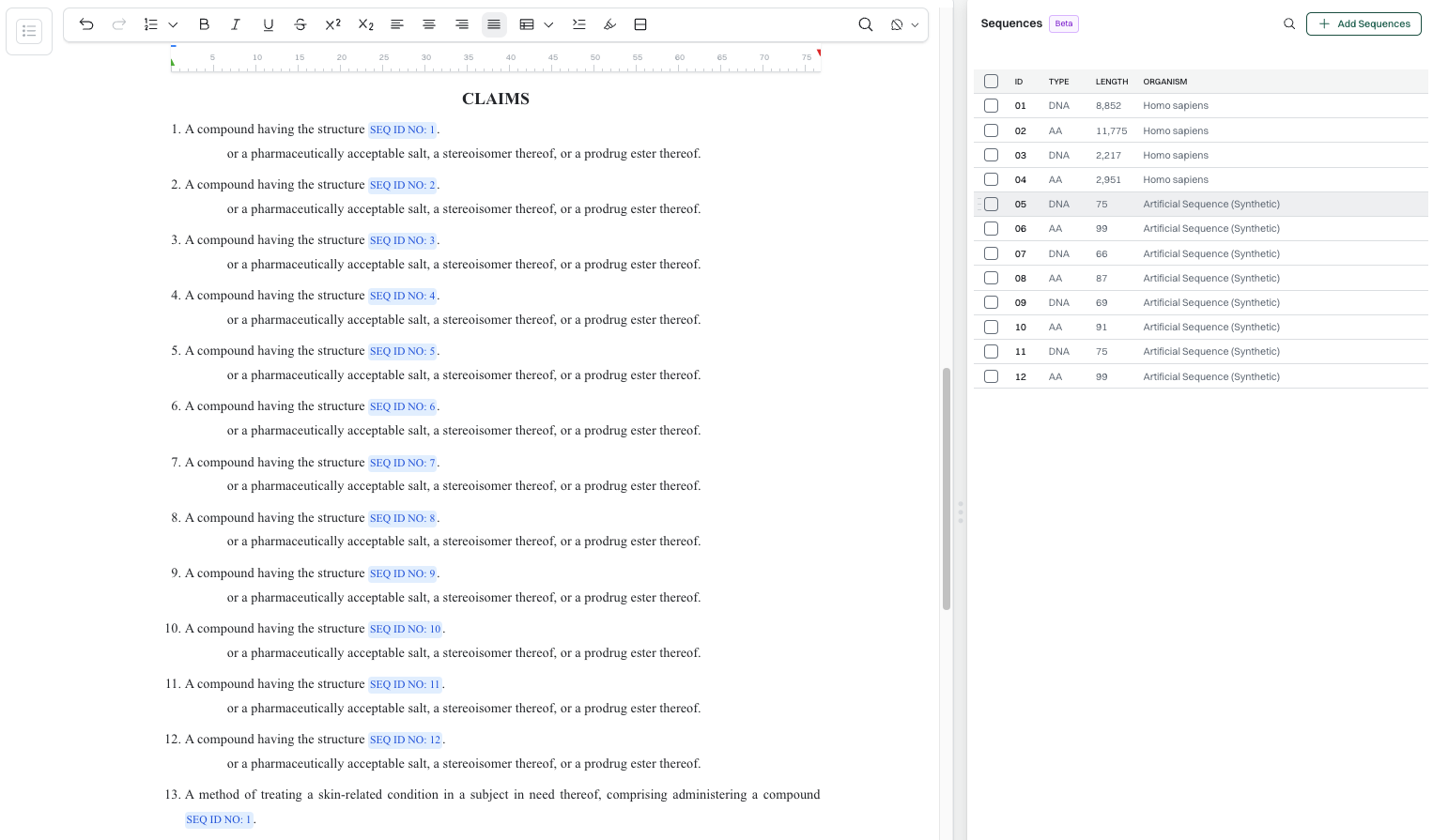
Patlytics now allows practitioners to import biological sequences, either by pasting them directly or by uploading a document for automatic extraction. Once imported, each sequence is treated as a privileged context object in the system, rather than general text. It carries a fixed identity throughout the drafting workflow: Wherever Sequence 1 appears in an application, it refers to the same, verified object.
This approach solves both the volume and the precision problems. Sequences don't drift, get re-interpreted, or truncated. The object that enters the system is the object that appears in the claims - ultimately saving you time by reducing the amount of post-drafting QC checking.
Sequence Listing Management at a Glance:
- Sequence import via paste or document upload, with automatic extraction and locked-object handling across drafting
- Auto-propogation to specs when sequence IDs change
- ST.26-compliant sequence listing export (XML) for USPTO, EPO, and PCT filings
- Optimized performance for dense biotech specifications
Book a demo to see how Patlytics supports life sciences patent work across the full prosecution and litigation lifecycle.
Reduce cycle times. Increase margins. Deliver winning IP outcomes.
The Premier AI-Powered
Patent Platform











.png)
















